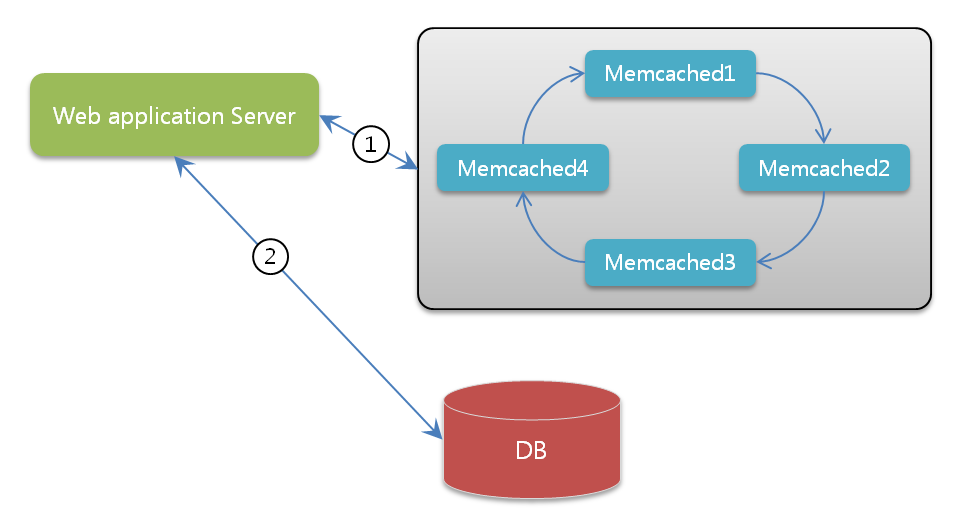
> memcached는 고성능의 분산 메모리 객체 캐싱 시스템으로 데이터베이스의 부하를 완화시켜 동적 웹어플리케이션의 속도를 향상 시킬 수 있다. 웹어플리케이션의 임시 데이터 저장용 메모리라고 할 수 있다.
>>> 장점
시스템의 사용되지 않는 일부 메모리를 활용할 수 있어 남는 자원을 효율적으로 사용해 성능을 향상 시킬 수 있다.
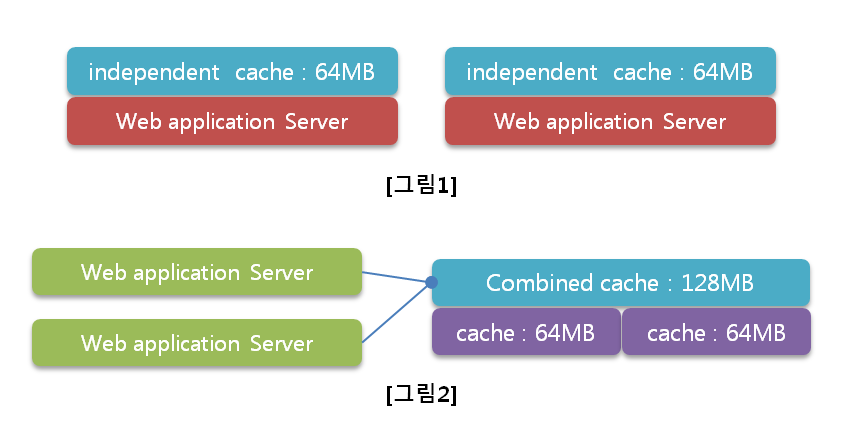 – 초창기의 캐시 시스템은 [그림1]과 같이 각노드가 완전히 독립적으로 운영되어 데이터를 조회 또는 저장시 어느서버를 이용할지 관리되어야 하며 용량의 제한으로 인해 비생산적이며 자원 낭비적인 시스템으로 구성되었다.
– 초창기의 캐시 시스템은 [그림1]과 같이 각노드가 완전히 독립적으로 운영되어 데이터를 조회 또는 저장시 어느서버를 이용할지 관리되어야 하며 용량의 제한으로 인해 비생산적이며 자원 낭비적인 시스템으로 구성되었다.
– memcached는 이러한 제약사항의 해결을 위한 메커니즘을 제공 하는데 [그림2]와 같이 consistent hash 알고리즘을 사용하여 물리적인 별도의 캐시서버를 로직상 하나의 서버로 보고 사용할 수 있도록 한다. 즉, 개발자는 서버의 대수와 상관없이 한개의 객체만을 활용하여 저장 및 조회하게 되므로 능률적이고 대용량의 캐시시스템을 갖게 되므로 활용도가 넓어질 수 있다. 또한 기업의 입장에서는 오래된 저사양 서버의 남는 메모리를 활용할 수 있게되 비용면에서 효율적일 수 있다.
>>> 단점
– 재부팅시 소멸되기 때문에 영구적인 저장용 시스템으로 활용할 수는 없으며 다시 데이터가 저장되는 기간동안은 디비에서 부하를 받아내야만 한다.
– 데이터 수정 및 삭제시 데이터베이스 & memcached에 동시에 진행되어야 하므로 개발 복잡도가 증가한다.
>>> 실무에서의 활용
– 기본적인 기능만을 제공하는 캐시서버 이기 때문에 일부에서는 redis와 비교해 기능이 부족하다고 지적하지만 활용하기에 따라 많은 범위에 활용될 수 있고 충분히 대량의 트래픽을 받아낼 수 있도록 구성할 수있다.