C++로 개발하기 위해서는 C에서 사용하던 문자열 다루는 방식 또한 이해해야 한다. 이유는 많은 코드들이 C스타일로 개발되어 왔기 때문에 알고 있어야 하는 부분이다.
#include "stdafx.h"
#include <iostream>
#include <cstring>
using namespace std;
void TestChar(char* pointer);
int _tmain(int argc, _TCHAR* argv[])
{
// 원본 문자열
char orgString[] = "TEST STRING";
// ※ 배열이름은 첫번째 문자열의 주소와 같다.
int orgStringLen = strlen(orgString);
int orgStringAddrLen = strlen(&orgString[0]);
cout << "STRING_LENGTH : " << orgStringLen << " :: " << orgStringAddrLen << "\n";
// 대상 문자열
// - strlen함수는 마지막 NULL문자는 포함하지 않고 카운트하므로 +1을 해준다.
char* tarString = new char[orgStringLen+1];
// 문자열 복사
// Error - This function or variable may be unsafe. Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
// strcpy(tarString, orgString);
// ※ 안전한 스트링 함수의 사용 : tarString크기를 넘어서는 메모리 복사를 방지
strcpy_s(tarString, orgStringLen + 1, orgString);
// 문자열 출력
// ※ 배열이름은 첫번째 문자열의 주소라고 하였으나 문자열이 출력되는 이유는?
// ==> 문자열의 첫번째 바이트의 주소가 전체 문자열을 지칭하기 때문
cout << "ORG_STRING : " << orgString << "\n";
cout << "TAR_STRING : " << tarString << "\n";
// 배열이름이 첫번째 문자열의 주소가 되어 문제가 되는점
// - TestChar함수에서는 문자열인지 문자인지 알수가 없다.
char singleChar = 'A';
char multiChar[] = "ABCDEFG";
TestChar(&singleChar);
TestChar(multiChar);
// 문자열 비교
if (strcmp(orgString, tarString) == 0){
cout << "compare \"" << orgString << "\" :::: \"" << tarString << "\" indentical.\n";
}
else
{
cout << "compare \"" << orgString << "\" :::: \"" << tarString << "\" not indentical.\n";
}
// 문자열 결합
char addString[] = "+ADD STRING";
int addStringLen = strlen(addString);
// int addStringLen = strlen(&addString[0]);
char* tempString = new char[orgStringLen + addStringLen + 1];
// 문자열 복사 + 결합
// Error - This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
// strcat(orgString, addString);
// ※ 안전한 스트링 함수의 사용 : tarString크기를 넘어서는 메모리 복사를 방지
strcpy_s(tempString, orgStringLen + addStringLen + 1, orgString);
strcat_s(tempString, orgStringLen + addStringLen + 1, addString);
if (strcmp(tarString, tempString) == 0){
cout << "compare \"" << tarString << "\" :::: \"" << tempString <<"\" indentical.\n";
}
else
{
cout << "compare \"" << tarString << "\" :::: \"" << tempString << "\" not indentical.\n";
}
// 문자열 선언
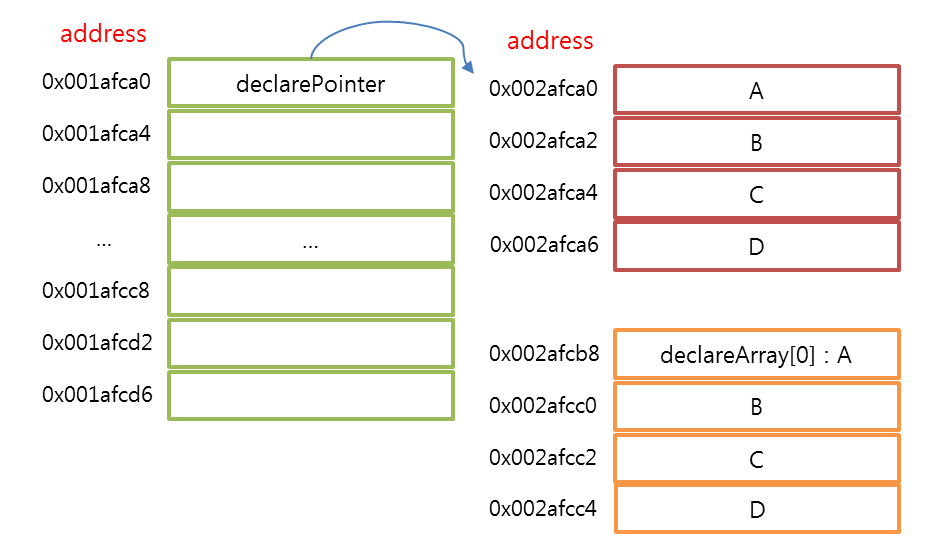
char declareArray[] = "ABCD";
char* declarePointer = "ABCD";
// 시작주소
void* startAddrArray = declareArray;
void* startAddrPointer = declarePointer;
// 끝주소
void* endAddrArray = declareArray+3;
void* endAddrPointer = declarePointer+3;
// 값의 출력 결과는 동일하지만 메모리에 저장되는 구조는 다르다.
// ==> pointer로 선언할 경우 문자열 덩어리를 가리키는 값이 메모리에 따로 저장됨
// ==> (&declarePointer != startAddrPointer)
cout << "Value : " << declareArray << "\n";
cout << "Array Addr : " << &declareArray << "(" << startAddrArray << "~" << endAddrArray << ")" << "\n";
cout << "Value : " << declarePointer << "\n";
cout << "Pointer Addr : " << &declarePointer << "(" << startAddrPointer << "~" << endAddrPointer << ")" << "\n";
return 0;
}
void TestChar(char* pointer)
{
// pointer는 단일문자인지 문자열인지 알수가 없다.
// ==> 해결책은 주석을 통해서 약속한다.
// pointer가 가리키는 변수가 단일문자라면
// NULL문자를 포함하고 있지 않기 때문에 쓰레기값이 뒤에 붙어서 출력된다.
cout << "TestChar : " << pointer << "\n";
// 단일 문자를 출력하기 위해서는 앞에 *를 붙인다.
cout << "TestChar : " << *pointer << "\n";
}
* 배열의 이름은 첫번째 문자열의 주소와 같다. ( orgString == &orgString[0] )
* strlen 함수는 마지막 NULL문자를 제외하고 카운트 하는 점을 유념한다.
* 문자열 함수를 다루는 법을 익힌다. (strlen, strcpy, strcmp, strcat)
* char declareArray[] = "ABCD"; char* declarePointer = "ABCD"; 두가지 선언법의 메모리 구조는 다르다. (아래그림 참조)
* 배열이름이 첫번째 문자열의 주소가 되기 때문에 유의해야 한다. (TestChar 함수의 주석 참조)